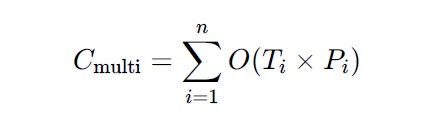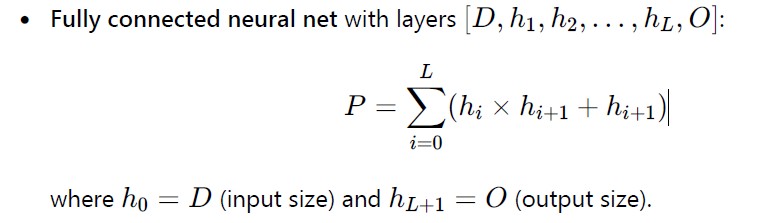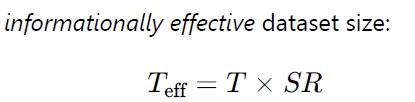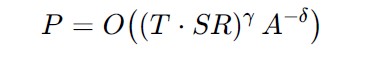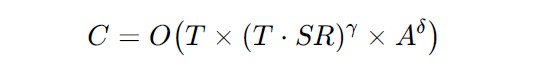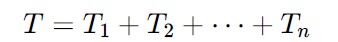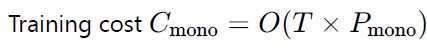We will create a somewhat concrete, yet still hypothetical example.
We’ll illustrate the total cost over a year (365 days) of operation for the following scenario:
The system is a free-roaming four legged front-loader robot.
It has two arms to handle parcels and packages. The arms have sensors for weight and surface characteristics – “gentle touch” not to crush materials or human operators.
The robot operates inside a facility, warehouse or factory. It has a visual, lidar and radar system for observing and navigating the environment. That is subsystem number 1, “Navigation”.
The front-loader has a system to handle propulsion, the four legs. That is subsystem 2, “propulsion”.
The front-loader has a system to handle the materials in the warehouse with the two arms. This is subsystem 3, “payload processing”.
The front-loader has a separate visual, audio and textual UI system for interacting with human workers in the facility or elsewhere (remote connection). The front loader’s UX is friendly and based on state of the art Human Computer Interface practices. This is subsystem 4, human interaction.
The front loader is re-trained every 24 hours, i.e. 365 times per year. The initial training material for subsystems 1-4 is almost completely disjoint. Each separate training material has a high signal to noise ratio. The system is expected to handle 20 human interactions and 10 parcel operations per hour.
With these characteristics, we will compare between all ML eggs in one model v.s. four disjoint models.
Architecture alternatives
A. Monolithic model
- One large multimodal model handling all subsystems jointly.
- Shared latent space across navigation, control, manipulation, and HCI.
- Retrained end-to-end every 24 hours.
B. Multimodel system
- Four specialist models:
- : Navigation
- : Propulsion
- : Payload processing
- : Human interaction
- Lightweight integration layer:
- Task router
- Shared state abstraction
- Each subsystem retrained independently every 24 hours.
Because training data is almost completely disjoint and each subset has a high signal to noise -ratio, this is a best-case scenario for modularization
Parameter and scaling assumptions
These are deliberately conservative and internally consistent.
Model sizes
Let:
- Monolithic model size:
- Each specialist (thanks to disjoint, high-SR data):
Total specialist parameters:
Modular storage is smaller, not larger. That is realistic in this case since domains barely overlap.
Training cost scaling
We’ll assume that training cost is proportional to the number of parameters P in a model.
Let one full training of the monolith cost:
Then per full retraining:
This reflects:
- smaller models,
- higher SR,
- no cross-domain entanglement.
Inference activity volume and cost
Per robot:
- Human interactions:
20×24×365=175,200 / year - Parcel ops:
10×24×365=87,600 / year
Assume each event requires:
- Monolith: full model inference
- Modular: 1–2 specialists activated, average = 1.5
Assume inference cost ∝ active parameters.
- Monolith inference cost per event:
- Modular inference cost per event:
That is ~4.4× cheaper per interaction for the Smart system based on multiple integrated models, or Docker for AI.
Almost there: Five-year Total Cost
Training cost (5 years)
| Architecture | Daily cost | Days | 5-year total |
|---|---|---|---|
| Monolithic | 1.0 | 1825 | 1825 |
| Multimodel | 0.6 | 1825 | 1095 |
Training savings: ~40%
Inference cost (5 years)
Total interactions per year:175,200+87,600=262,800
Five years:1.314×106events
| Architecture | Cost per event | 5-year total |
|---|---|---|
| Monolithic | 1.0 | 1,314,000 |
| Multimodel | 0.225 | 295,650 |
Inference savings: ~4.4×
Storage & integration (5 years)
| Component | Monolithic | Multimodel |
|---|---|---|
| Model storage | High (10B params) | Moderate (6B params) |
| Integration infra | Minimal | Moderate |
| Net effect | Baseline | +5–10% overhead |
We will conservatively add 100 cost units to multimodel TCO.
Final TCO comparison (5 years)
| Cost component | Monolithic | Multimodel |
|---|---|---|
| Training | 1,825 | 1,095 |
| Inference | 1,314,000 | 295,650 |
| Storage + integration | ~0 | +100 |
| Total TCO | ~1,315,825 | ~296,845 |
And conclusions:
So what did we do and say here?
We outlined a theoretical, yet plausible system, and compare two alternative ways to build that. The architectures we compared are a single large model that handles everything (monolith), and a system built of components, i.e small independent ML models that are integrated (multimodel architecture).
The multimodel architecture is ~4.4× cheaper over 5 years, dominated by inference cost savings.
Why modular wins decisively here
- Disjoint, high-signal domains
No representational duplication penalty. - Daily retraining
Training efficiency compounds strongly over time. - Sparse activation at inference
Only the relevant subsystem runs per task. - Embodied system
Most tasks are local (navigate, lift, talk), not global reasoning.
This is almost the ideal use case for modular intelligence.
In this scenario, a monolith is paying a tax for generality it does not use most of the time.