Ainolabs architecture for Continous Machine Learning Systems (CMLS) is designed to support non-interrupted operation, modular construction, system and data integrity, scalability in system design and operation and robust continuous operation.
These capabilities result in a machine learning system that can meet requirements on privacy, confidentiality and adapt to changing circumstances.
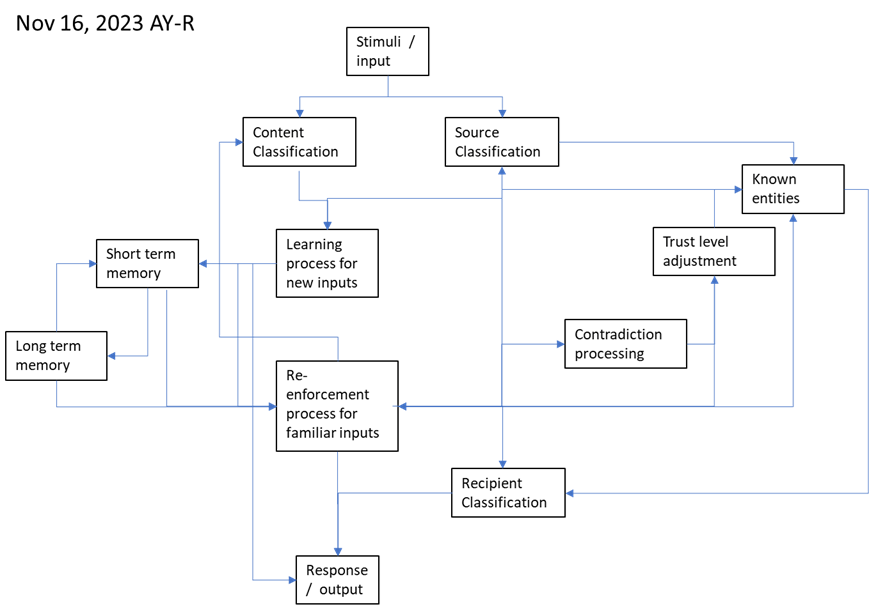
The blocks and the whole CMLS entity operate as a collection of re-enforcement learning engines. The individual inputs and outputs together with the memory blocks form a learning loop over time.
A CMLS receives inputs I0 … (to In, for discussion where an upper limit is needed). The CMLS responds with outputs O0 … On, again an endless sequence. Inputs and outputs match each other so that each Ii results on corresponding output Oi The system can produce an empty output.
The system uses the available memory blocks Short Term Memory and Long Term Memory to keep a log of inputs and outputs. This log is stored as memory imprints in the NN of memory blocks for this discussion. An implementation may also store a traditional transaction log; however that is not relevant to ML discussion.
The system uses each new Input Ik as an cumulative observation (feedback) of earlier input and output sequences I0 .. Ik-I and O0 … Ok-1. This provides a CMLS with an increasing set of cumulative experience that can be used to re-enforce earlier memories or resolve ambiguities and possible contradictions.
Input and Output sequences from 0 to k are marked as I(k) and O(k) in the rest of the text. These denote the ordered sets containing items 0 to k.
A transaction is defined as an Input – Output pair, i.e. Transaction = { I, O) and specifically Ti = { Ii, Oi }. The set of transactions 0 … i is marked as T[i].
CMLS Blocks explained
CMLS Blocks accept Inputs, process those using Output drafts and finally after minimizing the overall Cost function send out the Output.
Output can be empty if the Input is not understood or the system decides it is appropriate to “no comments”.
Stimuli / input
Input is received via some digital channel. Input can represent anything, including but not limited to electromagnetic radiation, sound in any medium, video (images, separate from light), text, illustrations, diagrams or other information or signal occurring naturally or generated by humans.
Input is associated with information about its source. Source can be unknown. See Source Classification.
Content Classification
Content Classification attempts to label the content into classes stored in Long Term Memory. This classification is context dependent and is affected by recent stimuli. The specific effect depends on implementation and can be e.g. increasing or decreasing enforcement.
Content Classification can impact the memory imprint of Input both in Short Term Memory and Long Term Memory.
Source Classification
Source Classification attempts to label the Source of the Input. It uses information stored in Long Term Memory. Source Classification is context dependent.
Content Classification can impact the memory imprint of Input both in Short Term Memory and Long Term Memory.
Short term memory
Short Term Memory is keeps track of immediate input – output sequences and other transient pieces of information passing through the CMLS. It should be noted that unlike humans, a digital CMLS Short Term Memory is limited only by available computing power and data storage.
Short Term Memory overflows strong memory imprints to Long Term Memory when it is either full or the Input is a wide match with the Short Term Memory’s Neural Network (substantial part of STM’s neurons fire up).
Long term memory
Long Term Memory is the mass storage of CMLS. All permanent memory imprints are stored there. The capacity of Long Term Memory is essential for CMLS – the more synapses, the more knowledge.
Long Term Memory is essential for storage (learn), retrieval of information, and also for graceful forgetting. As CMLS is a digital device, there is no biological degradation. Graceful forgetting is intentional, and can be based on time, source, or other factors. Notably, Long Term Memory stores timestamps with new information and can fade or completely remove memories that are valid only for a limited period of time.
Short Term Memory has a substantial role in time-related graceful forgetting. Fleeting information is kept only in short term memory and will not leave an imprint on Long Term Memory at all. As an example, consider weather or traffic conditions day before yesterday. Those can be recalled for a few days, but now e.g. a month ago unless there was a specific and pressing reason to store the memories in Long Term Memory.
Learning process for new inputs
Learning process takes Input and associated Content and Source classifications and runs learning processes on Short Term Memory. See also Re-enforcement process.
Re-enforcement process for familiar inputs
The Classified Input could be familiar from the past. RE-enforcement checks that by retrieval from Long and Short Term memory. In case the Input is familiar, the existing memory, including metadata about Source, Time and other possibly relevant factors is re-enforced together with the current Input via a learning cycle to either or both memory blocks.
Known entities
Known Entities block relies on memory blocks to check if the current Source is known from the past. Known Entities will run a learning cycle on Short Term memory about new sources, and both memory blocks for existing entities.
See also Trust level adjustment.
Trust level adjustment
Trust level adjustment compares the current Input is compared with existing memories. If there are discrepancies between current Source and other Entities, and/or between the content. Trust levels to either current Source and/or familiar Entities are adjusted. Adjustment happens through a machine learning cycle on Short and Long Term Memory.
Trust adjustment is unique in impacting Long Term Memory direct in case of changing the trust on a Known Entity.
Contradiction processing
Contradiction Processing is activated to check if the Input and/or current Output draft is contradicting Long or Short Term Memory. In layman terms, Contradiction Processing is checking for disagreements, untruths, lies and differing belief structures for both content and source.
Contradiction Processing may impact Known Entities, Short Term Memory, Long Term Memory and the current Output draft. Contradiction Processing can trigger Trust Level Adjustment.
Contradiction Processing for Transaction Ti considers the full history T[i-1]. The NN is calibrated to minimize the possible difference between the new Input Ii and the tentative Output Oi with known history T[i-1]. Specific implementations can weigh information according to its age differently, which results in different degrees of graceful forgetting and learning new information.
Recipient Classification
The tentative Output may be fine tuned according to the expected Recipient (the party providing the Input). This may not always be possible direct, but system can make a difference between an anonymous party and Known entities.
Recipient is classified similar to the Source via Known Entities, and Trust Level Adjustment. Notably, if memories in Long Term Memory are labelled confidential to certain Entities, any Output candidate to a Recipient in the same Trust circle would be treated differently than Recipients not in the same trust circle.
Response / output
The CMLS is an Input – Output system with memory. Accordingly, each Input is matched with an Output. The Output can be empty if the CMLS determines it can’t provide a reasonable answer due to e.g. confidentiality or plain ignorance.
Output is generated gradually between the blocks. It is determined to be ready once the cost functions is acceptably low, or after a timeout. The timeout value can depend on the nature of the Input, but ultimately there is an upper limit to the time CMLS can take to respond to an Input.
Even if the Output is empty, the system may have generated memory imprints of the Input. Over time this is expected to result in learning and CMLS ability to eventually answer.
Conclusion
An architecture for building scalable systems from modules for machine learning systems has been presented. This is similar to the invention of a subroutine: It is not necessary to build a whole system into one model. Instead, working systems can be composed of Domain Specific Models that are set to interact in an efficient and suitable combination.
